
Nell’ambito della programmazione software, le tecniche di offuscamento servono per nascondere il codice applicativo vero e proprio (il cosiddetto payload) in modo da rendere vani, o quantomeno complessi, i tentativi di reverse engineering. I motivi possono essere molteplici e non necessariamente malevoli:
- uno di essi può essere la volontà di evitare la duplicazione del codice e quindi, in qualche modo, la pirateria e il furto di proprietà intellettuale;
- un altro motivo può essere a scopo di protezione, per evitare cioè che un hacker comprenda il funzionamento del codice e sfrutti la presenza di eventuali bug, in linea col paradigma “security by obscurity”;
- infine, ed è il motivo che in questo caso ci interessa di più, un attaccante malevolo che vuole rendere la vita difficile all’analista impedendogli l’analisi del malware allo scopo di capire il funzionamento ed estrarre indicatori importanti (come URL, nomi di file o chiavi di registro) oppure rendere vano l’uso dell’antivirus.
È interessante notare che, nei primi due scenari, il “buono” è il programmatore e il “cattivo” è il reverse engineer. Il buono cerca di trovare meccanismi di offuscamento del codice migliori possibili. Nel terzo scenario è il viceversa. Il buono cerca di trovare meccanismi di deoffuscamento migliori possibili. La cosa brutta è che i ricercatori che sono interessati ai primi due scenari (protezione della proprietà intellettuale e security by obscurity) rendono, senza volerlo, la vita più difficile al loro collega del terzo scenario (quello che cerca di studiare un malware).
Per uno scrittore di codice malevolo il santo graal è il FUD (Fully Undetectable), cioè la capacità di essere completamente non rilevabile da nessuno strumento e nessun analista. In questo modo, il malware può propagarsi indisturbato.
Da notare, inoltre, che codice sorgente e codice offuscato sono funzionalmente identici (cioè il behavior) dal punto di vista dell’utente, per quanto i due possano essere differenti da altri punti di vista, come ad esempio le performance, che di solito peggiorano con l’offuscamento. Nella frase sopra occorre far attenzione al fatto che è stato precisato che il punto di vista importante per definire l’equivalenza tra codice sorgente e codice offuscato è quello dell’utente, nel senso che i due non devono necessariamente essere funzionalmente identici in toto. Il codice offuscato può anche esporre un numero maggiore di funzionalità. L’importante è che quelle in più non siano osservabili da parte dell’utente.
Esistono dei metodi per poter analizzare il funzionamento del codice del malware, la difficoltà naturalmente consiste nello scoprire e nell’avere l’accortezza di controllare i programmi che si installano sul proprio device.
Indice degli argomenti
Tecniche di offuscamento: regole di base e software applicativi
In generale, l’offuscamento può essere fatto a più livelli:
- livello di rete, ad esempio frammentando i pacchetti in modo che, finché sono in transito, non abbiano un senso compiuto. Lo acquisteranno solo una volta riassemblati alla destinazione. Per evitare la rilevazione, il malware potrà essere diviso in pacchetti di dimensioni diverse, fuori fase, parzialmente sovrapposti, mescolati ad altri pacchetti che verranno scartati, oppure con intervalli di tempo lunghissimi tra un pacchetto e il successivo;
- livello di contenuto: in questo caso il malware, veicolato principalmente via HTTP, sfrutta le possibilità di codifica del contenuto (content-transfer-encoding) che offre il protocollo: criptazione via HTTPS, compressione via gzip, encoding con più set di caratteri (es. ASCII, UTF-8, UTF-7, UTF16LE, UTF16BE, UTF-32LE, UTF-32BE ecc.), Transfer Encoding, come chunked o token-extension e via dicendo;
- livello applicativo: si sfruttano le caratteristiche dell’applicazione (ad esempio il web browser) che parla in “HTML” e, in particolare, il modo in cui questo viene renderizzato, compilato o eseguito. Un modo può essere quello di suddividere il malware in diversi file sorgente, ad esempio .css e .js, che poi vengono riuniti e interpretati solo a destinazione. Un altro modo è quello di sfruttare le capacità di offuscamento di linguaggi come javascript. Un altro ancora è quello di sfruttare linguaggi di scripting proprietari come quelli di Adobe Acrobat o Flash. Questo tipo di offuscamento è particolarmente insidioso perché richiede che lo strumento di sicurezza che monitora il traffico e che, teoricamente, dovrebbe rilevare il malware, sia dotato esso stesso di logica applicativa, simile a quella di un web browser vero e proprio;
- livello eseguibile: in questo caso l’offuscamento è del codice eseguibile del malware vero e proprio ed è quello che vedremo meglio tra un attimo.
I tipi di software utilizzati per fare offuscamento appartengono a tre categorie principali:
- packer, la forma più semplice di offuscamento è la compressione. In questo caso il file viene decompresso in memoria all’atto della sua esecuzione (runtime packer). Exeinfo PE è uno strumento capace di rilevare questi software;
- crypter, usano la criptazione, sia a chiave singola che doppia, per rendere incomprensibili l’intero file o sue parti;
- protector: è un termine “ombrello” che spesso comprende più livelli di protezione dal reverse engineering come l’applicazione sia della compressione che della criptazione oppure la virtualizzazione del codice (un esempio è WProtect).
I meccanismi più usati per offuscare il codice
Tra i meccanismi più spesso usati per l’offuscamento possiamo citare:
- l’OR esclusivo (XOR) è forse il metodo di offuscamento più comune per la sua semplicità di implementazione. È simmetrico e reversibile, quindi è sufficiente una sola funzione per criptare e decriptare il che si traduce in una dimensione minore del file. Nella sua forma base, si fa l’operazione logica XOR tra il testo di partenza e un valore dato, di lunghezza 1 byte. Facciamo un esempio, basandoci sulla XOR Truth Table. Facciamo l’XOR tra i caratteri “L”= 0x4C (codifica ASCII in esadecimale)= 01001100 e ”‘m”= 0x6D= 01101101. Il risultato è 00100001 = 0x21 = “!”. In versioni più avanzate, tale operazione può essere eseguita più volte con valori diversi a ogni passaggio oppure sezioni diverse del testo possono essere messe in XOR con valori diversi l’una dall’altra o addirittura ogni carattere con un valore diverso, partendo da un valore base e autoincrementandolo di 1 (ad esempio, si può fare l’ XOR della lettera “h” con 0x55, poi la lettera “t” con 0x56 e così via). Esistono software come XORSearch in grado di ricercare stringhe in file binari codificati XOR, ROL, ROT o SHIFT.

La XOR Truth Table che agevola l’applicazione del meccanismo di OR esclusivo nell’offuscamento del codice di un malware.
- la codifica Base64 è un sistema di codifica largamente usato per la conversione di dati binari in formato testuale utilizzando 64 caratteri ASCII (A-Z, a-z, 0-9, + e /, con il segno = usato come carattere padding). Di solito, uno degli elementi di riconoscibilità è proprio il carattere di padding;
- ROT13 è un sistema di codifica molto semplice, basato sul cifrario di Cesare, e il suo nome sta per ROTate 13 dal momento che sostituisce ogni lettera con la sua equivalente che sta 13 posti più avanti nell’alfabeto, ad es. “a” con “n”, “b” con “o” e così via. Ovviamente non è necessario usare solo 13 come valore chiave. Il valore 13 è speciale solo perché, in un alfabeto di 26 lettere, la stessa operazione può essere usata per la codifica e la decodifica, cioè ad es. “a” <-> “n”.

Alcuni esempi di offuscamento di codice (fonte).
Tecniche di offuscamento: modi diversi di applicarle
Approcciando il problema in modo del tutto generale potremmo chiederci: quanti modi diversi ci sono per fare offuscamento? E dati due programmi offuscatori P e P’ come si fa a capire qual è il migliore tra essi?
Iniziamo prima dalla seconda domanda. Ci sono tre quantità che possono essere calcolate e che possono contribuire a misurare la qualità di un programma offuscatore:
- la potenza: misura quanta “oscurità” (a livello di un analista umano) viene aggiunta al programma di partenza dall’operazione di offuscamento. Per fare questo, è ovviamente necessario avere prima una misura del livello di oscurità di un programma. L’idea è che un software è tanto più oscuro quanto più è complesso e la complessità può essere misurata da varie grandezze tra cui la lunghezza del programma, la complessità ciclotomatica di McCabe, quanto le condizioni all’interno del programma sono annidate una dentro l’altra (ad es. una serie di if contenuti l’uno nell’altro), quanto sono complesse le strutture dati utilizzate nel software, quanti parametri ci sono in input nelle funzioni contenute, e così via. Se un programma offuscatore vuole essere potente deve agire su queste variabili, ad es. aggiungendo condizioni annidate, aumentando il numero di parametri di input nelle funzioni, allungando il programma, sconvolgendo la struttura del programma mettendo il più lontano possibile i punti di dichiarazione delle variabili e quelli dove esse vengono utilizzate e così via. Insomma l’obiettivo è rendere illeggibile un software;
- la resilienza: misura la difficoltà necessaria per deoffuscare il programma in modo automatico. Può andare da banale a one-way. In quest’ultimo caso vuole dire che non si riesce più a deoffuscare il programma. Essa dipende da due fattori:
- programmer effort: quanto tempo occorre a un programmatore per costruire un programma automatico deoffuscatore in grado di ridurre la potenza di un software offuscato;
- deobfuscator effort: quanto tempo occorre al programma deoffuscatore costruito al passo precedente per ridurre la potenza di un software offuscato;
- il costo: è la capacità, o il tempo, di calcolo necessaria per effettuare il deoffuscamento di un programma offuscato. Detto in altro modo è l’overhead di calcolo che è aggiunto dall’offuscamento rispetto al programma originale.
La qualità complessiva di un programma offuscatore sarà una funzione delle tre quantità appena viste.
Veniamo ora alla prima domanda che ci eravamo posti, e cioè in quanti modi diversi si può offuscare un programma. La risposta dipende da:
- il tipo di informazione che l’offuscamento va a toccare;
- il tipo di trasformazione che viene fatta sui dati al punto precedente.
Faremo riferimento alla figura. In particolare potremmo avere:
- offuscamento della struttura: agisce sulla struttura del codice sorgente e, in particolare, sulla formattazione (ad esempio, rimuovendo tutti gli spazi), sui nomi delle variabili (ad esempio, trasformandole da nomi “parlanti” in nomi composti da caratteri random) e così via:
- aggregazione: calcoli che logicamente stanno insieme vengono messi in posizioni differenti e calcoli che non hanno relazioni gli uni con gli altri vengono messi insieme;
- ordinamento: l’ordine in cui i calcoli vengono fatti viene randomizzato;
- calcoli: viene inserito nuovo codice (ridondante o inutile) o vengono fatte modifiche algoritmiche al codice sorgente;
- offuscamento dei dati: l’obiettivo è quello di mascherare i dati (indici, array, strutture, parametri ecc.) ovunque si trovino nel programma:
- storage: le trasformazioni di questo tipo cercano di usare tipi di dati strani per immagazzinare i dati. Ad esempio, di solito se si deve scorrere gli elementi di un array si userebbe una variabile locale di tipo intero non negativo di dimensione appropriata ma niente esclude di utilizzare tipi diversi come ad esempio un oggetto di tipo intero. Un altro esempio consiste nella sostituzione di una stringa statica con una funzione che ha come output il valore della stringa;
- codifica: vengono utilizzate codifiche non naturali per tipi di dato comuni. Ad esempio, dovendo ciclare su un array di 1000 elementi la scelta più naturale sarebbe una variabile i cha va da 1 a 1000 ma niente impedisce di usare i’=8i + 3 con i’ che va da 11 a 8003;
- aggregazione: nei linguaggi orientati agli oggetti ci sono due modi per aggregare dati: in array e in oggetti. Due variabili intere di 32 bit, ad esempio, potrebbero essere la prima e la seconda parte di un’unica variabile a 64 bit Z(X,Y) = 2^32 Y + X. Nel caso di un array si possono fare varie operazioni per trasformarli: split (divisione di un array in più sub-array), merge (unione di due o più array in uno), fold (aumentare il numero di dimensioni di un array) o flatten (decrescere il numero di dimensioni di un array);
- ordinamento: in questo caso le trasformazioni consistono nel modificare l’ordinamento della dichiarazione delle variabili oppure degli elementi di un array;
- offuscamento del flusso: agisce sul flusso del programma alterandolo, ad es. inserendo codice ridondante o inessenziale, facendo modifiche agli algoritmi utilizzati, rendendo casuale l’esecuzione del codice ecc. Il prezzo da pagare è quasi sicuramente un peggioramento delle performance. L’idea di base è quello di rendere complesso il flusso con una serie di puntatori qua e là ai vari blocchi di codice. Un concetto che compare spesso in letteratura, in riferimento all’offuscamento del flusso di un programma, è quello di predicato opaco. Questa è una variabile booleana (True/False) in base al cui valore viene seguito un ramo del flusso piuttosto che un altro. Si chiama “opaco” perché l’esistenza di questa variabile è nota sia al programmatore che al deoffuscatore mentre il valore che assume (e quindi il ramo che viene percorso) è ben nota al programmatore ma non al deoffuscatore e lo sforzo che quest’ultimo deve fare per conoscerla, in termini di capacità di calcolo, è notevole. Inoltre con questa tecnica si mette fuori uso l’analisi statica perché la condizione viene valutata a runtime e quindi si potrà sapere il ramo che verrà percorso solo eseguendo il programma;
- trasformazioni preventive: questo tipo di trasformazioni differisce dalle trasformazioni dei dati o del flusso perché il suo obiettivo principale non è quello di oscurare il programma a un lettore umano ma di rendere il deoffuscamento automatico più complesso (trasformazioni preventive inherent) oppure di sfruttare problemi noti negli attuali deoffuscatori e decompilatori (trasformazioni preventive targeted):
- Inherent: sono trasformazioni a bassa potenza e alta resilienza come ad esempio eseguire dei loop al contrario, relativamente all’indice, e inserendo nel loop variabili inutili che cambiano valore con il progredire del loop. L’obiettivo è quello di aumentare la quantità di calcoli da fare;
- Targeted: un esempio era HoseMocha in grado di mandare in crash il decompilatore Java Mocha tramite l’aggiunta di un’opportuna istruzione dopo ogni return.
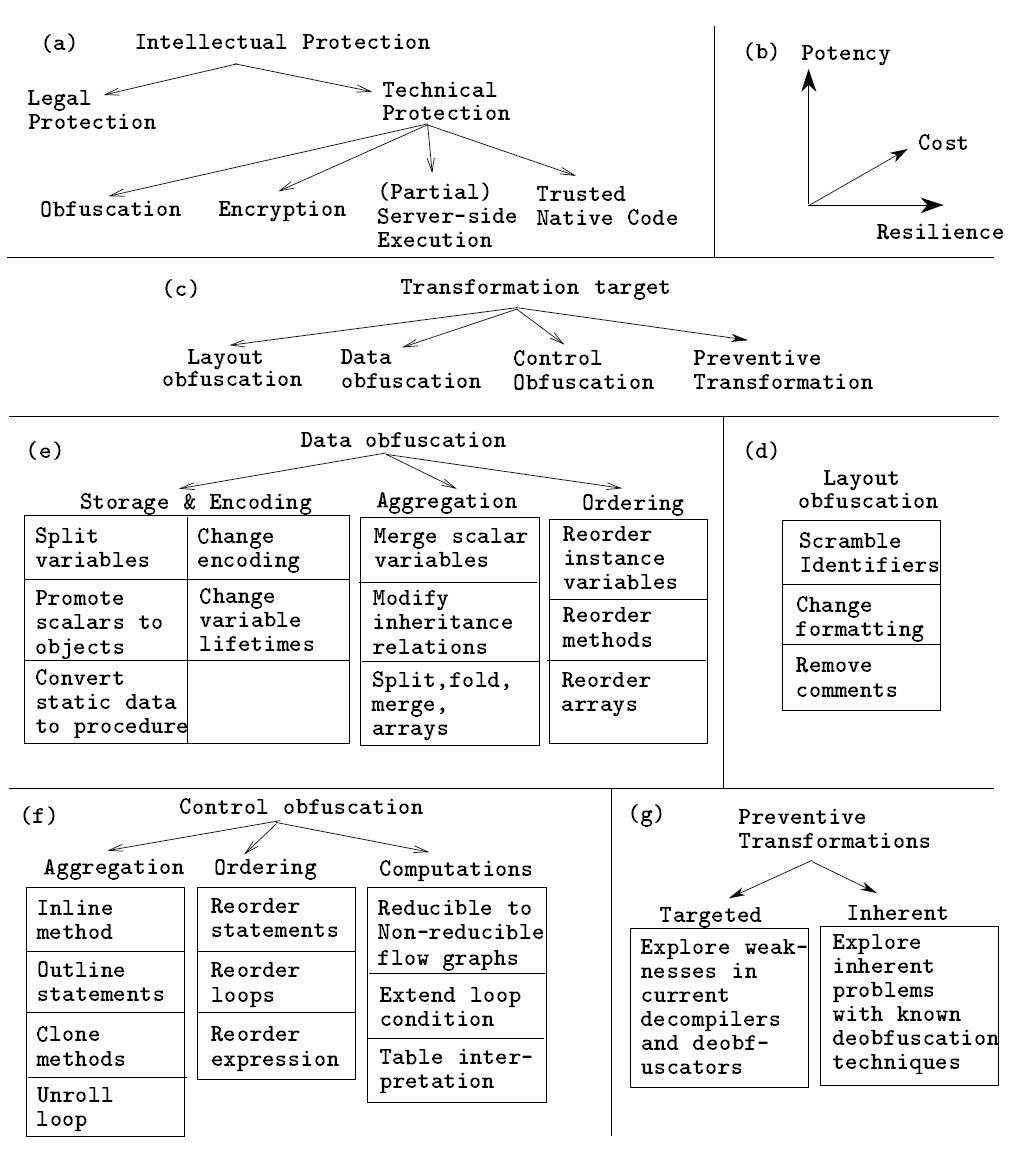
Modi diversi di offuscare un programma (fonte).
Per quanto abbiamo appena detto, in un programma offuscato il codice “reale” risulterà frammentato e sparso per tutto il corpo del programma intervallato da codice ridondante e inutile. Gli strumenti di program slicing aiutano il programmatore a decomporre il programma in blocchi gestibili denominati slice. Una slice di un programma P rispetto a un punto p e una variabile v consiste in tutti gli enunciati di P che hanno contribuito al valore di v nel punto p. Così, un program slicer estrarrà dal programma offuscato gli enunciati dell’algoritmo che calcola una variabile opaca v anche se l’offuscatore ha sparso questi enunciati per tutto il programma.









