
Se in passato l’identità di un cittadino era univocamente attribuita ad ogni singolo individuo rispetto a pochi e importanti contesti della vita quotidiana (nazionale, politico, economico), negli ultimi anni ha acquisito una connotazione sempre più fluida e complessa a causa del rapido progresso tecnologico e del conseguente sviluppo dei mezzi di comunicazione di massa (social media, smartphone ecc.). Proprio questi strumenti ci consentono di avere molteplici identità digitali e, tramite queste, di vivere in numerosi ambiti virtuali e reali. Nello stesso tempo, però, ci espongono a nuove e complesse minacce.
Come primo passo, cercheremo di definire l’identità digitale con rimandi continui al GDPR, regolamento europeo (e legge italiana) per la protezione dei dati personali, per tentare di acquisire maggiore consapevolezza delle tutele poste in essere dalla legge e delle nostre reali necessità rispetto ad esse.
Le organizzazioni statali e private tendono a conservare informazioni affidabili atte a determinare univocamente l’identità di un individuo per erogare servizi tradizionali: sanità, anagrafe, scuola, trasporti, utilities.
Le informazioni usate per accedere ai servizi più innovativi (ad esempio i social media), invece, spesso sono più di quelle strettamente necessarie al loro uso, esponendoci a minacce di impiego illegittimo dei nostri dati. Nonostante il principio fondamentale a cui si ispira il legislatore sia la salvaguardia dei diritti e delle libertà delle persone, attraverso la protezione di tutti i dati personali (associati o associabili all’individuo), la superfice attaccabile risulta comunque troppo ampia.
Di sicuro la sociologia ci può aiutare a comprendere dinamiche complesse correlate all’identità digitale, intesa non solo come insieme ben definito di informazioni di identificazione della persona fisica in un determinato contesto digitale (ad esempio ID, username, e-mail, nickname ecc.), ma anche come insieme di informazioni che ne caratterizzano il comportamento (cronologia delle azioni, gusti dichiarati e non, media pubblicati ecc.). Queste ultime possono essere anche aggregate, elaborate e anonimizzate, ma non per questo il loro impatto sociale è ridotto e deve essere sottovalutato.
Il GDPR (Art. 5) afferma che “i dati personali sono raccolti per finalità determinate, esplicite e legittime”. Inoltre i dati personali devono essere adeguati, pertinenti e limitati a quanto necessario rispetto alle finalità per le quali sono trattati (“minimizzazione dei dati”). Nel contempo si afferma (Art. 6) la legittimità degli interessi del titolare del trattamento, tra cui campagne di marketing, analisi statistiche, campagne politiche e raccolta fondi. Sembra quasi una coperta troppo corta da gestire a priori con regole rigide.
Dunque la complessità del trattamento dei dati personali richiede che ne comprendiamo bene i meccanismi e le possibili implicazioni, al fine di assumere i comportamenti più opportuni per la nostra sicurezza.
Indice degli argomenti
Il problema della sicurezza
Il problema della sicurezza diventa: avere il controllo sul trattamento dei dati personali che idealmente dovrebbe essere limitato a quanto strettamente necessario all’uso di servizi specifici da parte dell’utente.
Tali restrizioni ridurrebbero la probabilità che si verifichino minacce alla sicurezza delle persone fisiche e gli eventuali danni che tali minacce possono causare (principio basilare dell’ingegneria della sicurezza).
In realtà, il trattamento viene delimitato considerando tutte le finalità di impiego dei dati considerate legittime. Tali finalità sono definite di volta in volta e tengono conto di diversi e numerosi interessi legittimi (GDPR, Art. 6), compresi quelli del titolare del trattamento che in genere coincidono con interessi specifici del business in questione.
- Lato utente / interessato al trattamento. La trasparenza e la consapevolezza dell’impiego dei dati è solo un primo passo. Ogni utente dovrà decidere se usare un determinato servizio in base ad una propria valutazione del rischio. Ma non tutti gli utenti hanno le capacità tecniche per determinare il livello di rischio reale, ad es. il miraggio di poter usufruire di servizi gratuiti, di larga diffusione e popolarità (social media) aumenta la tolleranza del rischio e ne cambia la percezione.
- Lato gestore del servizio / titolare del trattamento. Occorre una valutazione del rischio rispetto alla dimensione del problema e alle nuove minacce, per soddisfare compliance a leggi e normative, garantire la sicurezza degli utenti e salvaguardare gli obiettivi di business.
Coesistono, quindi, almeno due parti (possono intervenire anche terze parti a cui sono comunicati i dati) con diversi tipi di “risk appetite” o, meglio, diversi criteri per valutare il rischio e l’impatto del verificarsi di eventuali minacce.
Il rischio di sicurezza
Bisognerebbe realizzare un processo di analisi e gestione del rischio che coinvolga tutte le parti, ma ciò risulta estremamente complesso (per via del numero e della varietà degli attori coinvolti) e non obbligatorio per legge.
Un notevole miglioramento si avrebbe prevedendo una forma di partecipazione degli interessati o di loro rappresentanti alla DPIA (Data Protection Impact Assessment). Si otterrebbe una migliore valutazione del rischio e una maggiore consapevolezza da parte degli interessati stessi; come, per altro, indicato nella ISO/IEC 27005 (Information Risk Management) e accennato nel GDPR (Art. 35, comma 9).
È evidente che non risulta fattibile scendere in dettagli tecnici implementativi di architetture di sicurezza e delle loro vulnerabilità con gruppi numerosi di utenti, d’altro canto è fattibile ed efficace comunicare e condividere dei survey sulle minacce sociali e comportamentali analizzate rispetto ai processi di business che coinvolgono gli utenti.
Inoltre, ai fini della gestione del rischio di sicurezza settore per settore, i codici deontologici di riferimento menzionati nel GDPR potrebbero essere usati come metro per valutare l’adeguatezza dei trattamenti specifici, senza, però, dimenticare che si tratta di disposizioni non vincolanti.
Infine, dopo aver applicato corrette contromisure tecnologiche e di processo, ci si aspetterebbe che i rischi residui legati a reali minacce debbano essere condivisi e accettati in modo consapevole da tutte le parti. Anche questo aspetto farebbe parte di un processo ideale non sempre realizzabile (o realizzato).
In questo contesto dai contorni non ben definiti a priori, occorre analizzare bene scenari di minaccia con relative tecniche, tattiche e procedure, al fine di minimizzare i pericoli, averne maggiore consapevolezza e garantire la coesistenza degli interessi legittimi di tutte le parti in gioco.
Asset da proteggere: l’identità e i dati personali
Secondo il GDPR (Art. 4) i dati personali riguardano una persona fisica e ne consentono l’identificazione. La persona può essere identificata o identificabile attraverso la correlazione di tali dati. Dati anonimi non riconducibili a persone fisiche, non sono oggetto del GDPR.
Con tale definizione si tenta di tutelare il soggetto identificato o identificabile, in quanto non ci si limita alle informazioni utili all’identificazione diretta, ma a tutte quelle riconducibili all’interessato: quindi sue attività, messaggi, comunicazioni elettroniche audio e video e via dicendo.
Il principio è: i dati personali devono essere trattati in modo lecito e protetti per mezzo di adeguate contromisure… ma come è possibile applicarlo? E come dimostrare l’adeguatezza e l’efficacia delle soluzioni adottate?
Mentre risulta possibile definire bene i dati direttamente associati all’utente affinché possa usufruire di particolari servizi, risulta più difficile individuare e gestire i dati raccolti dal titolare del trattamento anche per suoi specifici e legittimi interessi (ad esempio, analisi statistica, profilazione per marketing e per migliore fruibilità del servizio), o per fornire servizi complessi a valore aggiunto (dati e funzionalità personalizzati). Tali dati personali possono essere pseudonimizzati, in questo caso consentono l’identificazione attraverso la correlazione di diverse banche dati. Oppure, possono essere anonimi, in quanto non riconducibili direttamente o indirettamente ad una persona fisica, “prendendo in considerazione l’insieme dei fattori obiettivi, tra cui costi e tempo necessario per l’identificazione, tenendo conto sia delle tecnologie disponibili al momento del trattamento, sia degli sviluppi tecnologici” (GDPR, par. 26). Come già detto in precedenza, i dati anonimi non sono oggetto del GDPR.
La caratterizzazione degli aspetti della vita sociale di un individuo nel cyber spazio si basa su tutte le tipologie di dati visti sopra. Anche i dati anonimi, infatti, giocano un ruolo importante per definire i gruppi e le loro caratteristiche: convinzioni, trend emotivi, azioni collettive e via dicendo.
L’identità digitale non è dunque solamente personale ma anche sociale: l’individuo è parte integrante di un gruppo e può essere danneggiato in quanto parte di quel gruppo… direttamente e indirettamente.
Molte tecniche di Social Engineering si fondano non solo sulla identità intesa come dati identificativi e peculiari dell’individuo, ma anche su caratterizzazioni dei gruppi sociali cui appartiene.
Minacce più raffinate ed evolute considerano le cerchie sociali come asset da attaccare/influenzare per portare attacchi con conseguenze per le stesse e le cerchie connesse (ad es. movimenti di opinione che spostano voti durante elezioni politiche).
In sintesi l’identità digitale comprende:
- i dati personali di un individuo direttamente associati all’individuo;
- i dati personali pseudonimizzati;
- i dati derivati e anonimi ricavati dalle sue attività sociali.
Social attack surface: la superficie d’attacco dell’identità digitale
Per quanto concerne i dati personali di soggetti identificati o identificabili, la superficie di attacco, in generale, è costituita da tutte quelle tecnologie, processi organizzativi, procedure che ne determinano l’impiego in contesti di business.
È particolarmente interessante e doveroso esplorare anche gli aspetti di sicurezza dell’identità digitale che non sono così facilmente definibili a priori (aspetti sociali), ma che come abbiamo visto possono causare danni all’individuo diretti o indiretti.
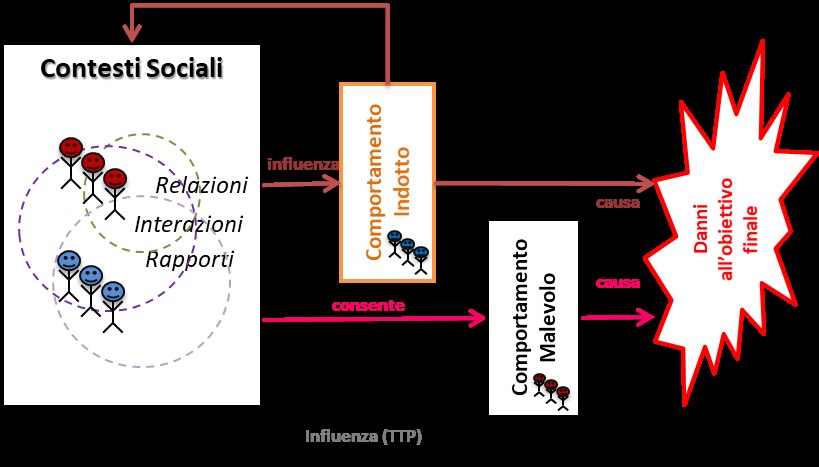
Schema di un tipico processo di attacco sociale.
In figura si è schematizzato un tipico processo di attacco sociale che ha come scenario social media e relativi utenti (vittime e attaccanti). I social media sono lo strumento e l’ambiente dell’attacco, essi aiutano a definire / modificare il contesto sociale. La sociologia, quindi, consente di individuare a che livello un attacco possa essere condotto (la superficie di attacco = contesto sociale):
- relazioni più o meno durature e con diverse connotazioni volute dalle persone che le stabiliscono;
- rapporti strutturali imposti agli individui, ad esempio da strutture organizzative;
- interazioni tra persone.
L’attaccante attraverso tecniche, tattiche e procedure:
- acquisisce informazioni sulla identità digitale relative al contesto sociale (dati personali collegati o collegabili a persone fisiche, dati anonimi su gruppi o persone);
- Influenza e modifica il contesto sociale delle vittime sfruttando mezzi quali: tecnologie (ad esempio Phishing), denaro, affettività, imposizione di presunte regole, persuasione, manipolazione, fiducia ecc.;
- agisce direttamente o induce azioni malevoli consapevoli o inconsapevoli per i propri fini.
Azioni malevoli di questo tipo inducono, ad esempio, comportamenti in individui inconsapevoli che diventano strumenti diretti per il raggiungimento degli obiettivi dell’attaccante oppure forniscono informazioni che consentono all’attaccante di poter effettuare azioni malevoli verso il vero target dell’attacco.
È facile comprendere come il processo di: azione malevola –> azione indotta –> azione malevola –> azione indotta ecc., possa essere complesso a piacere sia nel “tempo” (iterazioni successive) che nello “spazio” (coinvolgimento di sempre più persone o gruppi). Il processo dipende dalla complessità e dall’intensità dell’effetto finale che si vuole ottenere.
La definizione di contromisure efficaci non può che vedere un sempre maggior coinvolgimento dell’utente (consapevolezza dei rischi e supporto al contrasto delle minacce) e includere la caratterizzazione sempre più precisa delle minacce stesse anche con l’impiego di tecnologie innovative di machine learning.
Conclusione
Al fine di difendere l’individuo come essere del cyber spazio, è dunque necessario non solo identificare adeguate e innovative contromisure a livello tecnico e tecnologico per proteggere i dati personali, ma diffondere una cultura ed una consapevolezza sempre più profonda dei meccanismi dannosi che si possono innescare attraverso azioni individuali nel cyber spazio.
Ogni individuo può così determinare e gestire meglio il rischio a cui si espone (in base ai propri personali interessi e caratteristiche) che molto spesso risulta difficile o quasi impossibile da gestire in totale autonomia, da parte del titolare del trattamento.










